将来の使用のためにMLモデルを保存する
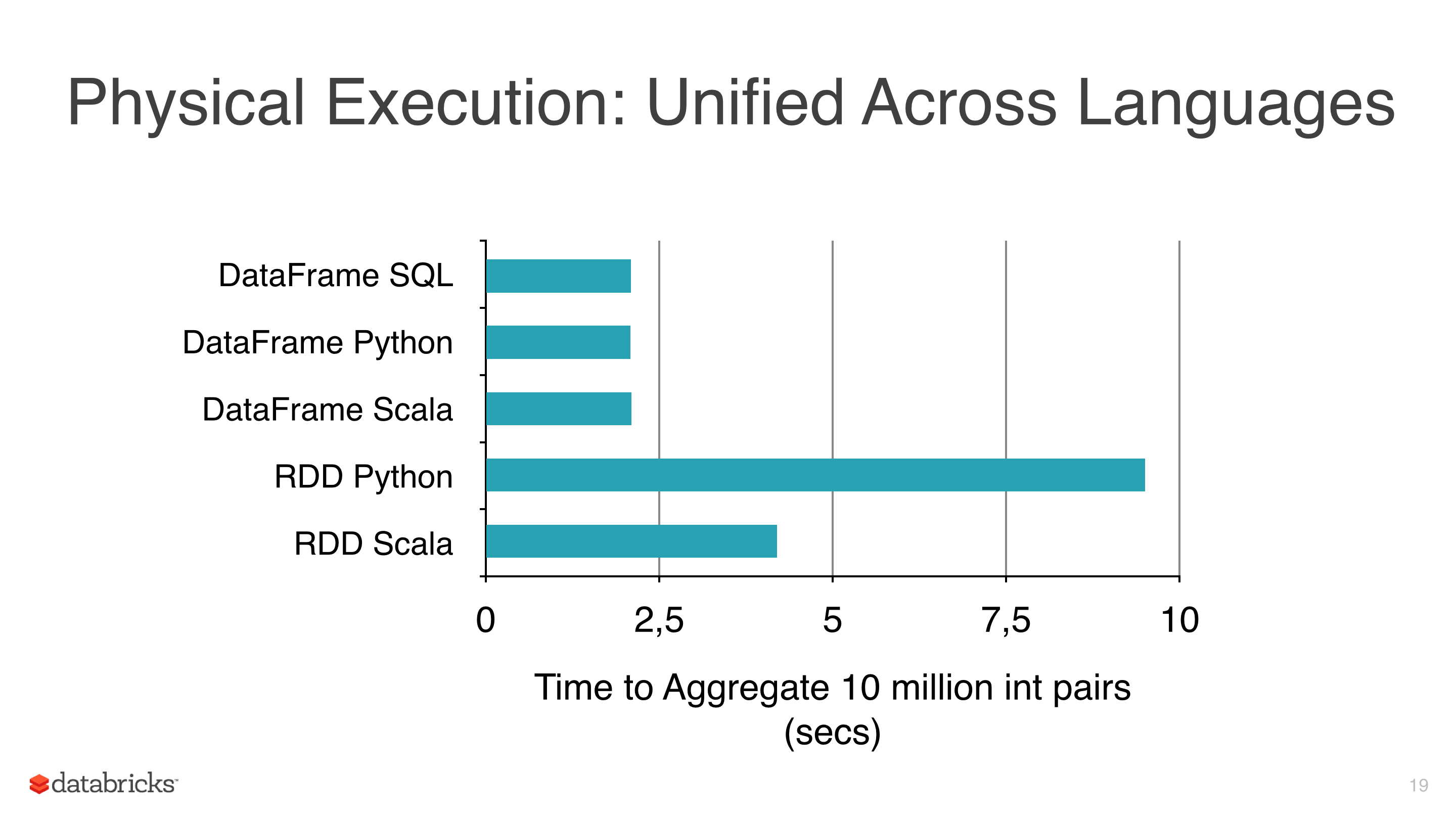
線形回帰、ロジスティック回帰、Naive Bayesなどの機械学習アルゴリズムを一部のデータに適用していましたが、RDSの使用を避け、DataFramesの使用を開始しようとしました RDDsは遅い 写真1を参照してください。
私がDataFramesを使用しているもう1つの理由は、mlライブラリには CrossValidator というモデルを調整するのに非常に役立つクラスがあるためです。このクラスは適合後にモデルを返します。明らかに、このメソッドはいくつかのシナリオをテストする必要があり、その後、 適合モデル (パラメーターの最適な組み合わせ)を返します。
私が使用するクラスターはそれほど大きくなく、データはかなり大きく、フィッティングには数時間かかるので、後で再利用するためにこのモデルを保存したいのですが、どうやって私が無視しているのかわかりませんか?
ノート:
- Mllibのモデルクラスにはsaveメソッドがあります(つまり NaiveBayes )が、mllibにはCrossValidatorがなく、RDDを使用するため、計画的にそれを避けています。
- 現在のバージョンはspark 1.5.1。
Spark 2.0.0+
一見、すべてのTransformersとEstimatorsは、次のインターフェースで MLWritable を実装します。
def write: MLWriter
def save(path: String): Unit
および MLReadable 次のインターフェイス
def read: MLReader[T]
def load(path: String): T
これは、モデルをディスクに書き込むためにsaveメソッドを使用できることを意味します。たとえば、
import org.Apache.spark.ml.PipelineModel
val model: PipelineModel
model.save("/path/to/model")
後で読む:
val reloadedModel: PipelineModel = PipelineModel.load("/path/to/model")
同等のメソッドは、PySparkでも MLWritable / JavaMLWritable および MLReadable /で実装されています JavaMLReadable それぞれ:
from pyspark.ml import Pipeline, PipelineModel
model = Pipeline(...).fit(df)
model.save("/path/to/model")
reloaded_model = PipelineModel.load("/path/to/model")
SparkRは write.ml / read.ml 関数を提供しますが、現在のところ、これらは他のサポートされている言語と互換性がありません- SPARK-15572 。
ローダークラスは、保存されている PipelineStage のクラスと一致する必要があることに注意してください。たとえば、LogisticRegressionModelを保存した場合、LogisticRegressionModel.loadではなくLogisticRegression.loadを使用する必要があります。
Spark <= 1.6.0を使用していて、モデルの保存に関する問題が発生した場合は、バージョンを切り替えることをお勧めします。
Spark固有のメソッドに加えて、Spark独立メソッドを使用してSpark MLモデルを保存およびロードするように設計されたライブラリが増えています。たとえば、 Spark MLlibモデルの提供方法 を参照してください。
Spark> = 1.6
Spark 1.6以降、saveメソッドを使用してモデルを保存できます。ほぼすべてのmodelが MLWritable インターフェイスを実装しているためです。たとえば、 LinearRegressionModel に含まれているため、それを使用してモデルを目的のパスに保存することができます。
スパーク<1.6
ここで間違った仮定をしていると思います。
DataFramesの一部の操作は最適化でき、通常のRDDsと比較してパフォーマンスが向上します。 DataFramesは効率的なキャッシュを提供し、SQLish APIはRDD APIよりも間違いなく理解しやすいでしょう。
MLパイプラインは非常に有用であり、クロスバリデーターやさまざまなエバリュエーターなどのツールは、どのマシンパイプラインでも必要不可欠です。上記のどれも特に難しいものではない場合でも、低レベルMLlib APIの上に実装することをお勧めします普遍的で比較的よくテストされたソリューションを使用します。
これまでのところは良いですが、いくつかの問題があります。
DataFramesやselectのようなwithColumnの簡単な操作がわかる限り、mapのようなRDDと同等のパフォーマンスを表示します。- 場合によっては、一般的なパイプラインの列数を増やすと、適切に調整された低レベルの変換と比較してパフォーマンスが実際に低下する可能性があります。もちろん、それを修正するために途中でdrop-column-transformersを追加できます。
ml.classification.NaiveBayes単なるラッパー のmllibAPIを含む多くのMLアルゴリズム、- PySpark ML/MLlibアルゴリズムは、実際の処理をScalaに対応するものに委任します。
- 最後になりましたが、DataFrame APIの背後に隠れていても、RDDはまだ存在しています。
結局のところ、MLLibを介してMLを使用することで得られるものは、非常にエレガントで高レベルのAPIだと思います。できることの1つは、両方を組み合わせてカスタムマルチステップパイプラインを作成することです。
- mLを使用してデータをロード、クリーンアップ、変換し、
- 必要なデータを抽出し(たとえば extractLabeledPoints メソッドを参照)、
MLLibアルゴリズムに渡します。 - カスタム相互検証/評価を追加する
- 選択したメソッドを使用して
MLLibモデルを保存します(Sparkモデルまたは [〜#〜] pmml [〜#〜] )
これは最適なソリューションではありませんが、現在のAPIを考えると最良のソリューションです。
モデルを保存するAPI機能が現在実装されていないようです( Spark issue tracker SPARK-6725 を参照)。
代替が投稿されました( モデルをML PipelineからS3またはHDFSに保存する方法? )これは、単にモデルをシリアル化することを含みますが、Javaアプローチです。 PySparkでは、同様のことができます。つまり、モデルをピクルしてディスクに書き込みます。