ASCIIコードの順序付けの背後にあるロジックはありますか?
私は工学を勉強している弟にCを教えていました。さまざまなデータ型が実際にメモリに格納される方法を彼に説明していました。符号付き/符号なしの数値と10進数の浮動小数点ビットの背後にあるロジスティクスについて説明しました。 Cでのchar型について説明しているときに、ASCIIコードシステムと、charが1バイトの数値として格納される方法についても説明しました。
彼はなぜ「A」にASCIIコード65が与えられ、他には何も与えられていないのかと私に尋ねました。同様に、なぜ「a」にコード97が具体的に与えられているのですか?大文字と小文字の範囲の間に6つのASCIIコードのギャップがあるのはなぜですか?私はこれを知りませんでした。これは私にも大きな好奇心を生み出したので、私がこれを理解するのを手伝ってくれませんか。私はこれまでこのトピックについて論じた本を見つけたことがありません。
この背後にある理由は何ですか? ASCIIコードは論理的に編成されていますか?
主にASCIIコードを変換しやすくするために、歴史的な理由があります。
数字(0x30から0x39)には、2進接頭辞110000が付いています。
0 is 110000
1 is 110001
2 is 110010
したがって、プレフィックス(最初の2つの「1」)を消去すると、2進化10進数の数字になります。
大文字の接頭辞は1000000です。
A is 1000001
B is 1000010
C is 1000011
同様に、プレフィックス(最初の「1」)を削除すると、アルファベットで索引付けされた文字(Aは1、Zは26など)になります。
小文字には2進接頭辞1100000が付いています。
a is 1100001
b is 1100010
c is 1100011
など。上記と同じ。したがって、大文字に32(100000)を追加すると、小文字になります。
このチャートは、ウィキペディアからそれを非常によく示しています。下部の上部2のコントロール2の2つの列と、その他で埋められたギャップに注目してください。 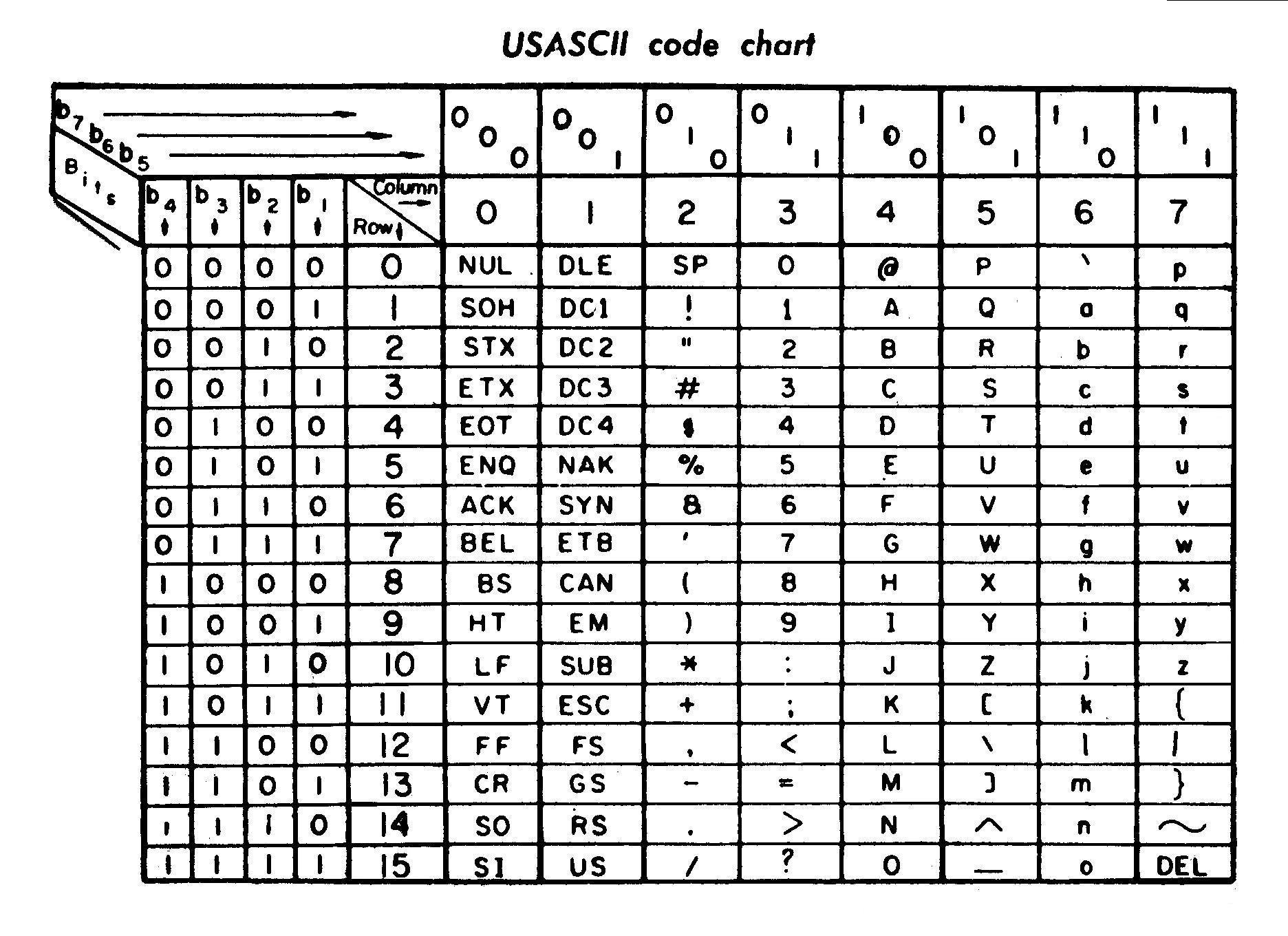
また、ASCIIは以前に通過したものに基づいて開発されたことにも注意してください。ASCIIの歴史の詳細については、 Tom Jenningsによるこのすばらしい記事 を参照してください。見知らぬ人の制御文字のいくつかの意味と使用法が含まれています。
ASCIIコード: http://en.wikipedia.org/wiki/ASCII の非常に詳細な履歴と説明は次のとおりです。
要するに:
- ASCIIは、テレプリンターエンコーディング標準に基づいています
- 最初の30文字は「印刷不可」です-テキストの書式設定に使用されます
- 次に、大まかにキーボードに配置される順序で、印刷可能な文字を続けます。キーボードを確認してください:
- スペース、
- 数字の大文字の大文字記号:!、 "、#、...、
- 数字
- 通常、数字付きのキーボード行の最後に配置される記号-大文字
- 大文字、アルファベット順
- 記号は通常、キーボードの行の最後に文字で配置されます-大文字
- アルファベット順の小文字
- 通常、キーボードの行の最後に文字が付いた記号-小文字
Aとaの間の距離は32です。これはかなり丸い数字ですね。
大文字と小文字の6文字のギャップは、(32-26)= 6であるためです(注:英語のアルファベットには26文字あります)。
- 「A」は16進数で0x41です。
- 「a」は16進数で0x61です。
- '0'から '9'は、16進数で0x30-0x39です。
したがって、少なくともA、a、および0-9の番号を覚えるのは簡単です。記号がわかりません。 ASCII注文 に関するウィキペディアの記事を参照してください。
'a'と 'A'のバイナリ表現を見ると、1ビットだけ異なることがわかります。これは非常に便利です(大文字を小文字に、またはその逆に変換するだけで、ビット)。なぜそこから具体的に始めるのか、私にはわかりません。
ウィキペディア :
コード自体は、ほとんどの制御コードが一緒になり、すべてのグラフィックコードが一緒になるように構成されていました。最初の2列(32桁)は制御文字用に予約されていました。[14]ソートアルゴリズムを簡単にするために、グラフィックの前に「スペース」文字を付ける必要があったため、位置0x20になりました。[15]委員会は、大文字の64文字のアルファベットをサポートすることが重要であると判断し、ASCIIを構造化して、使用可能な64文字のグラフィックコードセットに簡単に縮小できるようにすることを選択しました。[16]小文字したがって、大文字と小文字はインターリーブされませんでした。小文字やその他のグラフィックのオプションを開いたままにするために、文字の前に特殊コードと数値コードを配置し、文字「A」を0x41の位置に配置してドラフトと一致させました。対応する英国の標準。[17] 0〜9の数字は、011で始まるバイナリの値に対応するように配置されているため、バイナリコード化された10進数で簡単に変換できます。