LinkedHashMapの内部実装はHashMap実装とどのように違いますか?
HashMapには次の実装があると読みました。
main array
↓
[Entry] → Entry → Entry ← linked-list implementation
[Entry]
[Entry] → Entry
[Entry]
[null ]
そのため、Entryオブジェクトの配列があります。
質問:
同じhashCodeで異なるオブジェクトの場合、この配列のインデックスは複数のEntryオブジェクトをどのように格納できるのかと思っていました。
これは
LinkedHashMap実装とどう違いますか? mapの二重リンクリスト実装ですが、上記のような配列を維持し、次および前の要素へのポインターをどのように格納しますか?
そのため、
Entryオブジェクトの配列があります。
ではない正確に。 Entryオブジェクトの配列チェーンがあります。 HashMap.Entryオブジェクトにはnextフィールドがあり、Entryオブジェクトをリンクリストとしてチェーンできます。
HashCodeが同じでもオブジェクトが異なる場合、この配列のインデックスは複数の
Entryオブジェクトをどのように格納できるのだろうと思っていました。
(質問の図が示すように)Entryオブジェクトは連鎖しているためです。
これは
LinkedHashMap実装とどう違いますか? mapの二重リンクリスト実装ですが、上記のような配列を維持し、次および前の要素へのポインターをどのように格納しますか?
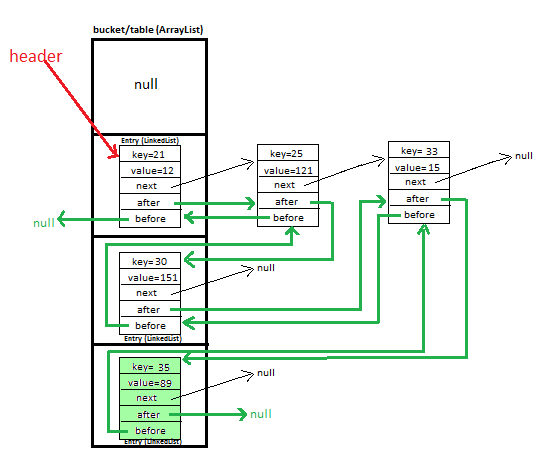
LinkedHashMap実装では、LinkedHashMap.EntryクラスはHashMap.Entryクラス。beforeおよびafterフィールドを追加します。これらのフィールドは、LinkedHashMap.Entryオブジェクトを、挿入順序を記録する独立した二重リンクリストに入れます。したがって、LinkedHashMapクラスでは、エントリオブジェクトは2つの異なるチェーンにあります。
メインハッシュ配列を介してアクセスされる単一リンクハッシュチェーン、および
エントリ挿入順序で保持されるすべてのエントリの個別の二重リンクリスト。
HashMapは挿入順序を維持しないため、二重にリンクされたリストは維持しません。
LinkedHashMapの最も顕著な特徴は、キーと値のペアの挿入順序を維持することです。 LinkedHashMapは、そのために二重のリンクリストを使用します。
LinkedHashMapのエントリは次のようになります。
static class Entry<K, V> {
K key;
V value;
Entry<K,V> next;
Entry<K,V> before, after; //For maintaining insertion order
public Entry(K key, V value, Entry<K,V> next){
this.key = key;
this.value = value;
this.next = next;
}
}
Beforeおよびafterを使用することにより、LinkedHashMapに新しく追加されたエントリを追跡します。これは、挿入順序を維持するのに役立ちます。
前のエントリを参照する前と後は、LinkedHashMapの次のエントリを参照します。
図とステップごとの説明については、 http://www.javamadesoeasy.com/2015/02/linkedhashmap-custom-implementation.html を参照してください。
ありがとう。
look を自分で取ってください。後で参照するために、Googleで次のことを実行できます。
Java LinkedHashMapソース
HashMapはLinkedListを使用して衝突を処理しますが、HashMapとLinkedHashMapの違いは、LinkedHashMapに予測可能な反復順序があることです。通常、キーの挿入順序を維持する追加の二重リンクリストによって実現されます。例外は、キーが再挿入された場合です。その場合、リストの元の位置に戻ります。
参考として、LinkedHashMapを反復処理するほうがHashMapを反復処理するよりも効率的ですが、LinkedHashMapを使用するとメモリ効率が低下します。
上記の説明から明らかでない場合、ハッシュプロセスは同じであるため、通常のハッシュの利点が得られますが、二重リンクリストを使用しているため、上記の反復の利点も得られますEntryオブジェクトの順序を維持します。これは、あいまいな場合に備えて、衝突のハッシュ処理中に使用されるリンクリストとは無関係です。
EDIT:(OPのコメントに応じて):
A HashMapは、衝突を処理するためのEntryオブジェクトのチェーンを含むいくつかのスロットの配列に支えられています。すべての(key、value)ペアを反復処理するには、配列内のすべてのスロットを通過してからLinkedLists;を通過する必要があります。したがって、全体の時間は容量に比例します。
LinkedHashMapを使用する場合、必要なことは二重リンクリストをトラバースするだけなので、全体の時間はサイズに比例します。
他の答えはどれも、このようなものを実装する方法を実際に説明していないので、試してみましょう。
1つの方法は、ハッシュキーに挿入された前の要素と次の要素への参照を持つ、ユーザーには見えない(キーと値のペアの)値に追加情報を持たせることです。利点は、一定の時間で要素を削除できることです。ハッシュマップからの削除は一定の時間であり、この場合、エントリへの参照があるため、リンクリストからの削除は削除されます。ハッシュマップの挿入は一定であり、リンクリストは通常はないため、一定時間で挿入できますが、この場合、リンクリスト内のスポットに一定時間アクセスできるため、一定時間で挿入でき、最後に取得は一定時間です構造のハッシュマップ部分のみを処理する必要があるためです。
このようなデータ構造は、コストなしでは得られないことに留意してください。ハッシュマップのサイズは、すべての余分な参照のために大幅に増加します。各メインメソッドは少し遅くなります(繰り返し呼び出される場合は問題になります)。また、データ構造の間接指定(実際の用語:Pであるかどうかはわかりません)は増加しますが、参照はハッシュマップ内のものを指すことが保証されているため、これは大したことではないかもしれません。
このタイプの構造の唯一の利点は、順序を保持することであるため、使用するときは注意してください。また、答えを読むとき、これがそれが実装されている方法であることはわかりませんが、タスクが与えられた場合にそれをどのように行うかはわかりません。
Oracle docs には、私の推測を確認する引用があります。
この実装は、すべてのエントリを介して実行される二重リンクリストを維持するという点でHashMapと異なります。
同じウェブサイトからの別の関連する引用。
このクラスは、オプションのMap操作をすべて提供し、null要素を許可します。 HashMapと同様に、ハッシュ関数がバケット間で要素を適切に分散すると仮定して、基本操作(追加、包含、削除)の一定時間のパフォーマンスを提供します。 1つの例外を除き、リンクリストを維持するための追加費用のため、パフォーマンスはHashMapのパフォーマンスをわずかに下回る可能性があります。 。 HashMapでの反復はより高価になる可能性が高く、その容量に比例した時間が必要です。