PHPでファイルから最後の行を読み取る最良の方法は何ですか?
私のPHPアプリケーションでは多くのファイルの終わりから始まる複数行を読む(ほとんどのログ)が必要です。最後の1つだけが必要な場合があります。基本的に、Unixのtailコマンドと同じくらい柔軟なものが必要です。
ファイルから最後の1行を取得する方法について質問があります(ただし、[〜#〜] n [〜#〜]行が必要です) 、さまざまなソリューションが提供されました。どれが最良で、どれがより良いパフォーマンスであるかはわかりません。
メソッドの概要
インターネットで検索したところ、さまざまなソリューションに出会いました。これらを3つのアプローチにグループ化できます。
- naive
file()を使用するものPHP function; - 不正行為システムで
tailコマンドを実行するもの。 - mighty
fseek()を使用して、開いているファイルを喜んでジャンプします。
素朴 one、a 不正行為 one、3個のmighty oneの5つのソリューションを選択(または作成)しました。
- 最も簡潔な naive solution 、組み込み配列関数を使用します。
tailcommand に基づく唯一の可能な解決策で、少し大きな問題があります:tailが利用できない場合は実行されません、非Unix(Windows)またはシステム機能を許可しない制限された環境で。- シングルバイトが、改行文字を検索(およびカウント)するファイルの最後から読み取られ、hereが見つかったソリューション。
- マルチバイトバッファリング大きなファイル用に最適化されたソリューションで、hereが見つかりました。
- 解決策#4のわずかに 修正されたバージョン バッファー長が動的で、取得する行数に応じて決定されます。
すべてのソリューション動作。あらゆるファイルから期待する結果を返すという意味で、私たちが要求する任意の行数について(大きなファイルの場合はPHPメモリ制限を破ることができるソリューション#1を除いて、何もありません。しかし、どちらが良いですか?
性能試験
質問に答えるために、テストを実行します。それがこれらのことをする方法ですよね?
サンプルを準備しました100 KBファイル/var/logディレクトリにあるさまざまなファイルを結合します。次に、PHPスクリプトを作成し、5つのソリューションのそれぞれを使用して1、2、..、10、20、... 100、200、... 、10ファイルの末尾からの行。各テストは10回繰り返され(5×28×10 = 14テストのように)、平均経過時間を測定しますマイクロ秒単位。
PHPコマンドを使用して、ローカル開発マシン(Xubuntu 12.04、PHP 5.3.10、2.70 GHzデュアルコアCPU、2 GB RAM))でスクリプトを実行します行インタプリタ。結果は次のとおりです。
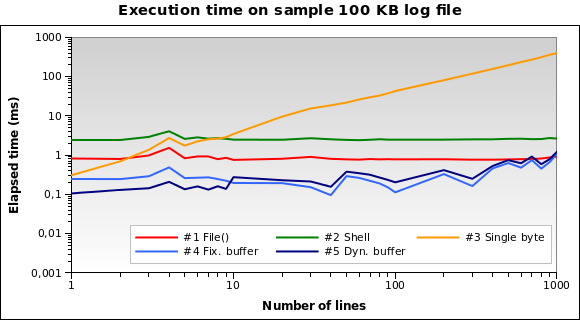
解決策#1と#2は悪いもののようです。解決策3は、数行を読む必要がある場合にのみ有効です。ソリューション#4と#5が最良のソリューションのようです。 動的バッファサイズがアルゴリズムを最適化する方法に注意してください。バッファが縮小されているため、数行の実行時間が少し短くなります。
大きなファイルを試してみましょう。10 MBログファイルを読み取る必要がある場合はどうなりますか?
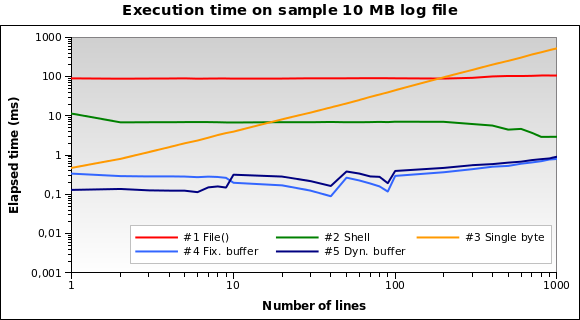
解決策1は、これよりもはるかに悪いものです。実際、10 MBのファイル全体をメモリにロードするのは良い考えではありません。 1MBと100MBのファイルでもテストを実行しましたが、実際には同じ状況です。
そして、小さなログファイルの場合?10 KBファイルのグラフは次のとおりです。
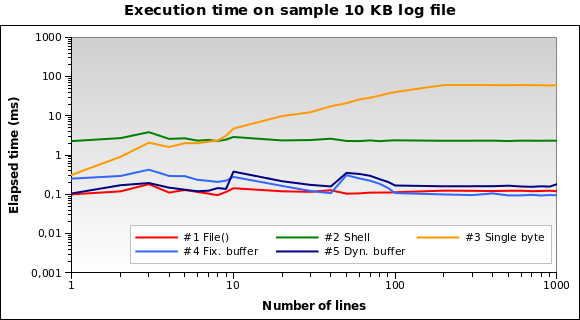
ソリューション#1が今最高です! 10 KBをメモリにロードすることは、PHPにとって大きな問題ではありません。また、#4と#5のパフォーマンスは良好です。ただし、これはエッジの場合です。10KBのログは、150/200行のようなものを意味します...
テストファイル、ソース、結果をすべてダウンロードできます here .
最終的な考え
Solution#5は、一般的な使用例に強くお勧めします。すべてのファイルサイズでうまく機能し、数行を読むときに特に優れたパフォーマンスを発揮します。
10 KBを超えるファイルを読み取る必要がある場合は、solution#1を避けてください。
解決策#2および#3は、実行する各テストに最適なものではありません:#2 2ミリ秒未満で実行されることはありません。#3は、要求する行数に大きく影響されます(1行または2行でのみ十分に機能します)。
これは変更されたバージョンで、最後の行もスキップできます。
/**
* Modified version of http://www.geekality.net/2011/05/28/php-tail-tackling-large-files/ and of https://Gist.github.com/lorenzos/1711e81a9162320fde20
* @author Kinga the Witch (Trans-dating.com), Torleif Berger, Lorenzo Stanco
* @link http://stackoverflow.com/a/15025877/995958
* @license http://creativecommons.org/licenses/by/3.0/
*/
function tailWithSkip($filepath, $lines = 1, $skip = 0, $adaptive = true)
{
// Open file
$f = @fopen($filepath, "rb");
if (@flock($f, LOCK_SH) === false) return false;
if ($f === false) return false;
if (!$adaptive) $buffer = 4096;
else {
// Sets buffer size, according to the number of lines to retrieve.
// This gives a performance boost when reading a few lines from the file.
$max=max($lines, $skip);
$buffer = ($max < 2 ? 64 : ($max < 10 ? 512 : 4096));
}
// Jump to last character
fseek($f, -1, SEEK_END);
// Read it and adjust line number if necessary
// (Otherwise the result would be wrong if file doesn't end with a blank line)
if (fread($f, 1) == "\n") {
if ($skip > 0) { $skip++; $lines--; }
} else {
$lines--;
}
// Start reading
$output = '';
$chunk = '';
// While we would like more
while (ftell($f) > 0 && $lines >= 0) {
// Figure out how far back we should jump
$seek = min(ftell($f), $buffer);
// Do the jump (backwards, relative to where we are)
fseek($f, -$seek, SEEK_CUR);
// Read a chunk
$chunk = fread($f, $seek);
// Calculate chunk parameters
$count = substr_count($chunk, "\n");
$strlen = mb_strlen($chunk, '8bit');
// Move the file pointer
fseek($f, -$strlen, SEEK_CUR);
if ($skip > 0) { // There are some lines to skip
if ($skip > $count) { $skip -= $count; $chunk=''; } // Chunk contains less new line symbols than
else {
$pos = 0;
while ($skip > 0) {
if ($pos > 0) $offset = $pos - $strlen - 1; // Calculate the offset - NEGATIVE position of last new line symbol
else $offset=0; // First search (without offset)
$pos = strrpos($chunk, "\n", $offset); // Search for last (including offset) new line symbol
if ($pos !== false) $skip--; // Found new line symbol - skip the line
else break; // "else break;" - Protection against infinite loop (just in case)
}
$chunk=substr($chunk, 0, $pos); // Truncated chunk
$count=substr_count($chunk, "\n"); // Count new line symbols in truncated chunk
}
}
if (strlen($chunk) > 0) {
// Add chunk to the output
$output = $chunk . $output;
// Decrease our line counter
$lines -= $count;
}
}
// While we have too many lines
// (Because of buffer size we might have read too many)
while ($lines++ < 0) {
// Find first newline and remove all text before that
$output = substr($output, strpos($output, "\n") + 1);
}
// Close file and return
@flock($f, LOCK_UN);
fclose($f);
return trim($output);
}
これも機能します:
$file = new SplFileObject("/path/to/file");
$file->seek(PHP_INT_MAX); // cheap trick to seek to EoF
$total_lines = $file->key(); // last line number
// output the last twenty lines
$reader = new LimitIterator($file, $total_lines - 20);
foreach ($reader as $line) {
echo $line; // includes newlines
}
またはLimitIteratorなし:
$file = new SplFileObject($filepath);
$file->seek(PHP_INT_MAX);
$total_lines = $file->key();
$file->seek($total_lines - 20);
while (!$file->eof()) {
echo $file->current();
$file->next();
}
残念ながら、あなたのテストケースは私のマシン上でセグメンテーション違反を起こしているので、どのように動作するかわかりません。
このすべてをここで読んだ後、私の小さなコピーペーストソリューション。 tail()は$ fpを閉じません。とにかくCtrl-Cでそれを殺さなければなりません。 CPU時間を節約するためのusleep。これまではWindowsでのみテストされていました。このコードをクラスに入れる必要があります!
/**
* @param $pathname
*/
private function tail($pathname)
{
$realpath = realpath($pathname);
$fp = fopen($realpath, 'r', FALSE);
$lastline = '';
fseek($fp, $this->tailonce($pathname, 1, false), SEEK_END);
do {
$line = fread($fp, 1000);
if ($line == $lastline) {
usleep(50);
} else {
$lastline = $line;
echo $lastline;
}
} while ($fp);
}
/**
* @param $pathname
* @param $lines
* @param bool $echo
* @return int
*/
private function tailonce($pathname, $lines, $echo = true)
{
$realpath = realpath($pathname);
$fp = fopen($realpath, 'r', FALSE);
$flines = 0;
$a = -1;
while ($flines <= $lines) {
fseek($fp, $a--, SEEK_END);
$char = fread($fp, 1);
if ($char == "\n") $flines++;
}
$out = fread($fp, 1000000);
fclose($fp);
if ($echo) echo $out;
return $a+2;
}
次の方法が好きですが、最大2GBのファイルでは機能しません。
<?php
function lastLines($file, $lines) {
$size = filesize($file);
$fd=fopen($file, 'r+');
$pos = $size;
$n=0;
while ( $n < $lines+1 && $pos > 0) {
fseek($fd, $pos);
$a = fread($fd, 1);
if ($a === "\n") {
++$n;
};
$pos--;
}
$ret = array();
for ($i=0; $i<$lines; $i++) {
array_Push($ret, fgets($fd));
}
return $ret;
}
print_r(lastLines('hola.php', 4));
?>
さらに別の機能として、正規表現を使用してアイテムを分離できます。使用法
$last_rows_array = file_get_tail('logfile.log', 100, array(
'regex' => true, // use regex
'separator' => '#\n{2,}#', // separator: at least two newlines
'typical_item_size' => 200, // line length
));
関数:
// public domain
function file_get_tail( $file, $requested_num = 100, $args = array() ){
// default arg values
$regex = true;
$separator = null;
$typical_item_size = 100; // estimated size
$more_size_mul = 1.01; // +1%
$max_more_size = 4000;
extract( $args );
if( $separator === null ) $separator = $regex ? '#\n+#' : "\n";
if( is_string( $file )) $f = fopen( $file, 'rb');
else if( is_resource( $file ) && in_array( get_resource_type( $file ), array('file', 'stream'), true ))
$f = $file;
else throw new \Exception( __METHOD__.': file must be either filename or a file or stream resource');
// get file size
fseek( $f, 0, SEEK_END );
$fsize = ftell( $f );
$fpos = $fsize;
$bytes_read = 0;
$all_items = array(); // array of array
$all_item_num = 0;
$remaining_num = $requested_num;
$last_junk = '';
while( true ){
// calc size and position of next chunk to read
$size = $remaining_num * $typical_item_size - strlen( $last_junk );
// reading a bit more can't hurt
$size += (int)min( $size * $more_size_mul, $max_more_size );
if( $size < 1 ) $size = 1;
// set and fix read position
$fpos = $fpos - $size;
if( $fpos < 0 ){
$size -= -$fpos;
$fpos = 0;
}
// read chunk + add junk from prev iteration
fseek( $f, $fpos, SEEK_SET );
$chunk = fread( $f, $size );
if( strlen( $chunk ) !== $size ) throw new \Exception( __METHOD__.": read error?");
$bytes_read += strlen( $chunk );
$chunk .= $last_junk;
// chunk -> items, with at least one element
$items = $regex ? preg_split( $separator, $chunk ) : explode( $separator, $chunk );
// first item is probably cut in half, use it in next iteration ("junk") instead
// also skip very first '' item
if( $fpos > 0 || $items[0] === ''){
$last_junk = $items[0];
unset( $items[0] );
} // … else noop, because this is the last iteration
// ignore last empty item. end( empty [] ) === false
if( end( $items ) === '') array_pop( $items );
// if we got items, Push them
$num = count( $items );
if( $num > 0 ){
$remaining_num -= $num;
// if we read too much, use only needed items
if( $remaining_num < 0 ) $items = array_slice( $items, - $remaining_num );
// don't fix $remaining_num, we will exit anyway
$all_items[] = array_reverse( $items );
$all_item_num += $num;
}
// are we ready?
if( $fpos === 0 || $remaining_num <= 0 ) break;
// calculate a better estimate
if( $all_item_num > 0 ) $typical_item_size = (int)max( 1, round( $bytes_read / $all_item_num ));
}
fclose( $f );
//tr( $all_items );
return call_user_func_array('array_merge', $all_items );
}