属性のように辞書キーにアクセスする?
obj.fooの代わりにobj['foo']として辞書キーにアクセスする方が便利だと思うので、このスニペットを書きました:
class AttributeDict(dict):
def __getattr__(self, attr):
return self[attr]
def __setattr__(self, attr, value):
self[attr] = value
しかし、Pythonがこの機能をそのまま提供していないのには、何らかの理由があるはずです。このように辞書キーにアクセスする際の注意点と落とし穴は何でしょうか。
これを行うための最良の方法は次のとおりです。
class AttrDict(dict):
def __init__(self, *args, **kwargs):
super(AttrDict, self).__init__(*args, **kwargs)
self.__dict__ = self
いくつかの長所:
- それは実際にうまくいきます!
- 辞書クラスのメソッドは隠されていません(例えば
.keys()は問題なく動作します)。 - 属性と項目は常に同期しています
- 存在しないキーに属性として正しくアクセスしようとすると、
AttributeErrorではなくKeyErrorが発生します。
短所:
.keys()のようなメソッドはnotになりますが、着信データで上書きされても問題ありません。- Python <2.7.4/Python3 <3.2.3では メモリリーク が発生します。
- Pylintは
E1123(unexpected-keyword-arg)とE1103(maybe-no-member)でバナナに行きます - 初心者にとっては純粋な魔法のようです。
これがどのように機能するかについての簡単な説明
- すべてのpythonオブジェクトはそれらの属性を
__dict__という名前の辞書に内部的に保存します。 - 内部辞書
__dict__が「単なる普通の辞書」である必要はないという要件はないので、dict()の任意のサブクラスを内部辞書に割り当てることができます。 - 今回の場合は、インスタンス化している
AttrDict()インスタンスを単純に代入します(__init__にあるように)。 super()の__init__()メソッドを呼び出すことによって、それが(すでに)辞書とまったく同じように振る舞うことを確認しました。なぜならその関数はすべての辞書インスタンス化コードを呼び出すからです。
Pythonがそのままこの機能を提供しない理由の1つ
"cons"リストに記されているように、これは保存されたキーの名前空間(任意の、そして/または信頼できないデータから来るかもしれません!)を組み込みのメソッド属性の名前空間と結合します。例えば:
d = AttrDict()
d.update({'items':["jacket", "necktie", "trousers"]})
for k, v in d.items(): # TypeError: 'list' object is not callable
print "Never reached!"
配列表記を使用すれば、キーの一部としてすべての有効な文字列を含めることができます。例えばobj['!#$%^&*()_']
From This other SO question 既存のコードを単純化する素晴らしい実装例があります。どうですか?
class AttributeDict(dict):
__getattr__ = dict.__getitem__
__setattr__ = dict.__setitem__
もっと簡潔で将来的にあなたの__getattr__と__setattr__関数に入るための余計な余地を残す余地はありません。
私は尋ねられた質問に答えます
なぜPythonは箱から出してそれを提供しないのですか?
私はそれが PythonのZen に関係しているのではないかと考えています。これは辞書から値にアクセスするための2つの明白な方法を作り出すでしょう:obj['key']とobj.key。
警告と落とし穴
これらには、コードの明確さの欠如と混乱の可能性があります。つまり、次のコードは、後日あなたのコードをメンテナンスするためにやってくる人、あるいはあなたが戻ってこないのであればあなたにさえ紛らわしいかもしれませんelseしばらくの間。繰り返しますが、 Zen :「読みやすさが重要です」から。
>>> KEY = 'spam'
>>> d[KEY] = 1
>>> # Several lines of miscellaneous code here...
... assert d.spam == 1
dがインスタンス化されている場合またはKEYが定義されている場合またはd[KEY]がd.spamの使用場所から離れて割り当てられている場合これは一般的に使用されている慣用句ではないため、行われていることについて混乱を招く可能性があります。私を混乱させる可能性があることを私は知っています。
さらに、KEYの値を次のように変更した場合(ただし、d.spamの変更を忘れた場合)は、次のようになります。
>>> KEY = 'foo'
>>> d[KEY] = 1
>>> # Several lines of miscellaneous code here...
... assert d.spam == 1
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
AttributeError: 'C' object has no attribute 'spam'
IMO、努力する価値はありません。
その他の項目
他の人が指摘したように、あなたは辞書キーとして(文字列だけではなく)どんなハッシュ可能オブジェクトも使うことができます。例えば、
>>> d = {(2, 3): True,}
>>> assert d[(2, 3)] is True
>>>
合法ですが、
>>> C = type('C', (object,), {(2, 3): True})
>>> d = C()
>>> assert d.(2, 3) is True
File "<stdin>", line 1
d.(2, 3)
^
SyntaxError: invalid syntax
>>> getattr(d, (2, 3))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: getattr(): attribute name must be string
>>>
そうではありません。これにより、辞書キーのすべての印刷可能文字またはその他のハッシュ可能オブジェクトにアクセスできます。これはオブジェクト属性にアクセスするときには持っていません。これは Python Cookbook(Ch。9) のレシピのように、キャッシュされたオブジェクトのメタクラスのような魔法を可能にします。
編集しているところ
私はspam.eggsよりspam['eggs']の美学を好む(私はそれがよりきれいに見えると思う)、そして私が namedtuple に出会ったとき私は本当にこの機能を切望し始めた。しかし、次のことができるという便利さはそれを上回ります。
>>> KEYS = 'spam eggs ham'
>>> VALS = [1, 2, 3]
>>> d = {k: v for k, v in Zip(KEYS.split(' '), VALS)}
>>> assert d == {'spam': 1, 'eggs': 2, 'ham': 3}
>>>
これは簡単な例ですが、私はobj.key表記法を使用する場合とは異なる状況で辞書を使用することがよくあります(つまり、XMLファイルから設定を読み込む必要がある場合)。他の場合、私は美的な理由で動的クラスをインスタンス化してその上にいくつかの属性を平手打ちしたいと思う場合、読みやすさを高めるために一貫性のために辞書を使い続けます。
私は、OPが長い間これを解決してきたと確信していますが、それでもこの機能が欲しい場合は、pypiから提供されているパッケージの1つをダウンロードすることをお勧めします。
束は、私がよく知っているものです。dictのサブクラスなので、あなたはそのすべての機能を持っています。- AttrDictもかなり良いように見えますが、私はそれに精通しているわけではないので、それほどソースを見ていません。私が持っているように細部 束 。
- Rotaretiによるコメントで述べられているように、Bunchは廃止予定ですが、Munchというアクティブなforkがあります。
しかしながら、彼のコードの読みやすさを向上させるために、彼はnot彼の記法スタイルを混ぜることを強く勧めます。もし彼がこの記法を好むなら、彼は単に動的オブジェクトをインスタンス化し、それに彼の望みの属性を追加し、そしてそれを毎日呼ぶべきです:
>>> C = type('C', (object,), {})
>>> d = C()
>>> d.spam = 1
>>> d.eggs = 2
>>> d.ham = 3
>>> assert d.__dict__ == {'spam': 1, 'eggs': 2, 'ham': 3}
コメントのフォローアップ質問に答える
下記のコメントでは、Elmoが尋ねています。
もっと深く行きたいとしたら? (タイプ(...)を参照)
私はこのユースケースを使ったことは一度もありませんが(ここでも、一貫性を保つためにdictをネストして使用する傾向があります)、次のコードが機能します。
>>> C = type('C', (object,), {})
>>> d = C()
>>> for x in 'spam eggs ham'.split():
... setattr(d, x, C())
... i = 1
... for y in 'one two three'.split():
... setattr(getattr(d, x), y, i)
... i += 1
...
>>> assert d.spam.__dict__ == {'one': 1, 'two': 2, 'three': 3}
警告emptor:いくつかの理由でこのようなクラスはマルチプロセッシングパッケージを壊すようです。私はこのSOを見つける前にしばらくの間このバグに苦しんでいました: pythonマルチプロセッシングで例外を見つける
もし__eq__や__getattr__のようなメソッドであるキーが欲しいとしたらどうでしょうか?
そして、あなたは文字で始まっていないエントリーを持つことができないでしょう、それでキーとして0343853を使うことはアウトです。
文字列を使いたくない場合はどうしますか?
標準ライブラリから便利なコンテナクラスを取り出すことができます。
from argparse import Namespace
コードビットをコピーする手間を省くため。標準の辞書アクセスはありませんが、本当に必要な場合は簡単に取り戻すことができます。 argparseのコードは単純です。
class Namespace(_AttributeHolder):
"""Simple object for storing attributes.
Implements equality by attribute names and values, and provides a simple
string representation.
"""
def __init__(self, **kwargs):
for name in kwargs:
setattr(self, name, kwargs[name])
__hash__ = None
def __eq__(self, other):
return vars(self) == vars(other)
def __ne__(self, other):
return not (self == other)
def __contains__(self, key):
return key in self.__dict__
タプルは辞書キーを使うことができます。あなたはどのようにあなたの構造の中でTupleにアクセスしますか?
また、 namedtuple は、属性アクセスを介して値を提供できる便利な構造です。
一般的には動作しません。すべての有効な辞書キーがアドレス指定可能な属性(「キー」)を作成するわけではありません。だから、あなたは注意する必要があります。
Pythonオブジェクトはすべて基本的に辞書です。だから私は多くのパフォーマンスや他のペナルティがあるとは思わない。
これは組み込みの collections.namedtuple を使った不変レコードの短い例です:
def record(name, d):
return namedtuple(name, d.keys())(**d)
そして使用例:
rec = record('Model', {
'train_op': train_op,
'loss': loss,
})
print rec.loss(..)
これは最初の質問には対処しませんが、私のように、この機能を提供するライブラリを探すときにここで終わる人々にとっては役に立つはずです。
Addictこれはこのための素晴らしいライブラリです。 https://github.com/mewwts/addict 注意してください以前の回答で述べた多くの懸念のうち。
ドキュメントからの例:
body = {
'query': {
'filtered': {
'query': {
'match': {'description': 'addictive'}
},
'filter': {
'term': {'created_by': 'Mats'}
}
}
}
}
常習者と:
from addict import Dict
body = Dict()
body.query.filtered.query.match.description = 'addictive'
body.query.filtered.filter.term.created_by = 'Mats'
Prodict 、Pythonの小さなクラス 私が書いた でそれらすべてを統治するのはどうでしょうか。
さらに、自動コード補完、再帰的オブジェクトインスタンス化、自動型変換が得られます。 !
あなたはまさにあなたが求めたことをすることができます:
p = Prodict()
p.foo = 1
p.bar = "baz"
例1:タイプヒント
class Country(Prodict):
name: str
population: int
turkey = Country()
turkey.name = 'Turkey'
turkey.population = 79814871
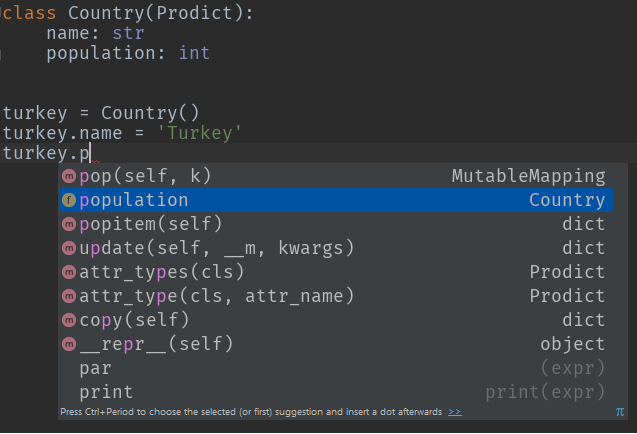
例2:自動型変換
germany = Country(name='Germany', population='82175700', flag_colors=['black', 'red', 'yellow'])
print(germany.population) # 82175700
print(type(germany.population)) # <class 'int'>
print(germany.flag_colors) # ['black', 'red', 'yellow']
print(type(germany.flag_colors)) # <class 'list'>
どうやらこれのためのライブラリがあるようです--- https://pypi.python.org/pypi/attrdict - この正確な機能に加えて再帰的なマージとjsonローディングを実装します。一見の価値があるかもしれません。
このスレッドからの入力に基づいてこれを作成しました。ただし、odictを使用する必要があるので、getおよびset attrをオーバーライドする必要がありました。私はこれが大部分の特殊用途に有効であると思う。
使い方は次のようになります。
# Create an ordered dict normally...
>>> od = OrderedAttrDict()
>>> od["a"] = 1
>>> od["b"] = 2
>>> od
OrderedAttrDict([('a', 1), ('b', 2)])
# Get and set data using attribute access...
>>> od.a
1
>>> od.b = 20
>>> od
OrderedAttrDict([('a', 1), ('b', 20)])
# Setting a NEW attribute only creates it on the instance, not the dict...
>>> od.c = 8
>>> od
OrderedAttrDict([('a', 1), ('b', 20)])
>>> od.c
8
クラス:
class OrderedAttrDict(odict.OrderedDict):
"""
Constructs an odict.OrderedDict with attribute access to data.
Setting a NEW attribute only creates it on the instance, not the dict.
Setting an attribute that is a key in the data will set the dict data but
will not create a new instance attribute
"""
def __getattr__(self, attr):
"""
Try to get the data. If attr is not a key, fall-back and get the attr
"""
if self.has_key(attr):
return super(OrderedAttrDict, self).__getitem__(attr)
else:
return super(OrderedAttrDict, self).__getattr__(attr)
def __setattr__(self, attr, value):
"""
Try to set the data. If attr is not a key, fall-back and set the attr
"""
if self.has_key(attr):
super(OrderedAttrDict, self).__setitem__(attr, value)
else:
super(OrderedAttrDict, self).__setattr__(attr, value)
これはスレッドですでに言及されているかなりクールなパターンですが、辞書を取り、それをIDEなどのオートコンプリートで動作するオブジェクトに変換したいだけの場合は、次のようにします。
class ObjectFromDict(object):
def __init__(self, d):
self.__dict__ = d
setattr() とgetattr()が既に存在するように自分自身を書く必要はありません。
クラスオブジェクトの利点は、おそらくクラスの定義と継承にあります。
答えに多少の違いを加えるために、 sci-kit learn はこれをBunchとして実装しています。
class Bunch(dict):
""" Scikit Learn's container object
Dictionary-like object that exposes its keys as attributes.
>>> b = Bunch(a=1, b=2)
>>> b['b']
2
>>> b.b
2
>>> b.c = 6
>>> b['c']
6
"""
def __init__(self, **kwargs):
super(Bunch, self).__init__(kwargs)
def __setattr__(self, key, value):
self[key] = value
def __dir__(self):
return self.keys()
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(key)
def __setstate__(self, state):
pass
必要なのはsetattrおよびgetattrメソッドを取得することだけです - getattrは辞書キーをチェックし、実際の属性をチェックすることに移ります。 setstaetは、ピクルスにする/束を外す「束」の修正のための修正です - チェックを忘れないなら https://github.com/scikit-learn/scikit-learn/issues/6196
Kinvaisの答えに基づいて構築されていますが、 http://databio.org/posts/python_AttributeDict.html で提案されているAttributeDictのアイデアを統合した別の実装を投稿しましょう。
このバージョンの利点は、入れ子になった辞書に対しても機能することです。
class AttrDict(dict):
"""
A class to convert a nested Dictionary into an object with key-values
that are accessible using attribute notation (AttrDict.attribute) instead of
key notation (Dict["key"]). This class recursively sets Dicts to objects,
allowing you to recurse down nested dicts (like: AttrDict.attr.attr)
"""
# Inspired by:
# http://stackoverflow.com/a/14620633/1551810
# http://databio.org/posts/python_AttributeDict.html
def __init__(self, iterable, **kwargs):
super(AttrDict, self).__init__(iterable, **kwargs)
for key, value in iterable.items():
if isinstance(value, dict):
self.__dict__[key] = AttrDict(value)
else:
self.__dict__[key] = value
class AttrDict(dict):
def __init__(self):
self.__dict__ = self
if __== '____main__':
d = AttrDict()
d['ray'] = 'hope'
d.Sun = 'shine' >>> Now we can use this . notation
print d['ray']
print d.Sun
Dict_to_obj https://pypi.org/project/dict-to-obj/ を使用できます
From dict_to_obj import DictToObj
a = {
'foo': True
}
b = DictToObj(a)
b.foo
True
解決策は次のとおりです。
DICT_RESERVED_KEYS = vars(dict).keys()
class SmartDict(dict):
"""
A Dict which is accessible via attribute dot notation
"""
def __init__(self, *args, **kwargs):
"""
:param args: multiple dicts ({}, {}, ..)
:param kwargs: arbitrary keys='value'
If ``keyerror=False`` is passed then not found attributes will
always return None.
"""
super(SmartDict, self).__init__()
self['__keyerror'] = kwargs.pop('keyerror', True)
[self.update(arg) for arg in args if isinstance(arg, dict)]
self.update(kwargs)
def __getattr__(self, attr):
if attr not in DICT_RESERVED_KEYS:
if self['__keyerror']:
return self[attr]
else:
return self.get(attr)
return getattr(self, attr)
def __setattr__(self, key, value):
if key in DICT_RESERVED_KEYS:
raise AttributeError("You cannot set a reserved name as attribute")
self.__setitem__(key, value)
def __copy__(self):
return self.__class__(self)
def copy(self):
return self.__copy__()
Dougが述べたように、obj.key機能を実現するために使用できるBunchパッケージがあります。実際には新しいバージョンがあります
それはあなたの辞書をそのneobunchify関数を通してNeoBunchオブジェクトに変換する素晴らしい機能を持っています。私はMakoテンプレートを多用し、NeoBunchオブジェクトとしてデータを渡すことでそれらをはるかに読みやすくするので、もしあなたがあなたのPythonプログラムで普通の辞書を使ってしまったがMakoテンプレートでドット表記を使いたいならあなたはそれを使うことができます:
from mako.template import Template
from neobunch import neobunchify
mako_template = Template(filename='mako.tmpl', strict_undefined=True)
data = {'tmpl_data': [{'key1': 'value1', 'key2': 'value2'}]}
with open('out.txt', 'w') as out_file:
out_file.write(mako_template.render(**neobunchify(data)))
そしてMakoテンプレートは以下のようになります。
% for d in tmpl_data:
Column1 Column2
${d.key1} ${d.key2}
% endfor
あなたは私が今作ったこのクラスを使ってそれをすることができます。このクラスを使用すると、他の辞書(jsonシリアル化を含む)のようにMapオブジェクトを使用することも、ドット表記を使用することもできます。お役に立てば幸いです。
class Map(dict):
"""
Example:
m = Map({'first_name': 'Eduardo'}, last_name='Pool', age=24, sports=['Soccer'])
"""
def __init__(self, *args, **kwargs):
super(Map, self).__init__(*args, **kwargs)
for arg in args:
if isinstance(arg, dict):
for k, v in arg.iteritems():
self[k] = v
if kwargs:
for k, v in kwargs.iteritems():
self[k] = v
def __getattr__(self, attr):
return self.get(attr)
def __setattr__(self, key, value):
self.__setitem__(key, value)
def __setitem__(self, key, value):
super(Map, self).__setitem__(key, value)
self.__dict__.update({key: value})
def __delattr__(self, item):
self.__delitem__(item)
def __delitem__(self, key):
super(Map, self).__delitem__(key)
del self.__dict__[key]
使用例
m = Map({'first_name': 'Eduardo'}, last_name='Pool', age=24, sports=['Soccer'])
# Add new key
m.new_key = 'Hello world!'
print m.new_key
print m['new_key']
# Update values
m.new_key = 'Yay!'
# Or
m['new_key'] = 'Yay!'
# Delete key
del m.new_key
# Or
del m['new_key']
これは私が使用するものです
args = {
'batch_size': 32,
'workers': 4,
'train_dir': 'train',
'val_dir': 'val',
'lr': 1e-3,
'momentum': 0.9,
'weight_decay': 1e-4
}
args = namedtuple('Args', ' '.join(list(args.keys())))(**args)
print (args.lr)
これは「良い」答えではありませんが、これは気の利いたものだと思いました(現在の形式では入れ子になった辞書を処理しません)。あなたの辞書を関数でラップするだけです。
def make_funcdict(d={}, **kwargs)
def funcdict(d={}, **kwargs):
funcdict.__dict__.update(d)
funcdict.__dict__.update(kwargs)
return funcdict.__dict__
funcdict(d, **kwargs)
return funcdict
今、あなたはわずかに異なる構文を持っています。辞書項目に属性としてアクセスするにはf.keyを実行します。通常の方法で辞書アイテム(および他の辞書メソッド)にアクセスするにはf()['key']を実行します。キーワード引数または辞書(あるいはその両方)を指定してfを呼び出すことで辞書を簡単に更新できます。
例
d = {'name':'Henry', 'age':31}
d = make_funcdict(d)
>>> for key in d():
... print key
...
age
name
>>> print d.name
... Henry
>>> print d.age
... 31
>>> d({'Height':'5-11'}, Job='Carpenter')
... {'age': 31, 'name': 'Henry', 'Job': 'Carpenter', 'Height': '5-11'}
そしてそれはあります。誰かがこの方法の長所と短所を提案してくれたらうれしいです。
このように辞書キーにアクセスする際の注意点と落とし穴は何でしょうか。
@Henryが示唆しているように、ドットアクセスが辞書で使用できない理由の1つは、辞書キーの名前をpythonに有効な変数に制限し、それによってすべての可能な名前を制限することです。
以下は、辞書dが与えられたときに、なぜドット付きアクセスが一般的に役に立たないのかの例です。
妥当性
次の属性はPythonでは無効になります。
d.1_foo # enumerated names
d./bar # path names
d.21.7, d.12:30 # decimals, time
d."" # empty strings
d.john doe, d.denny's # spaces, misc punctuation
d.3 * x # expressions
スタイル
PEP8の規約では、属性の命名には弱い制約が課せられます。
A.予約済み キーワード (または組み込み関数)名:
d.in
d.False, d.True
d.max, d.min
d.sum
d.id
関数の引数の名前が予約済みのキーワードと衝突する場合は、一般的に末尾にアンダースコアを1つ追加するのが良いでしょう...
変数名は関数名と同じ規則に従います。
d.Firstname
d.Country
読みやすさを向上させるために、必要に応じて、関数命名規則を使用してください。単語は小文字でアンダースコアで区切ります。
時々これらの懸念は パンダのようなライブラリ で提起され、それは名前によるDataFrameカラムの点アクセスを可能にします。命名制限を解決するためのデフォルトのメカニズムも、配列表記(大括弧で囲まれたストリング)です。
これらの制約があなたのユースケースに当てはまらない場合、 点アクセスデータ構造 にいくつかのオプションがあります。