サブドメインなしで有効なドメイン名に一致する正規表現とは何ですか?
まず、10,000番目のRegEx質問についてごめんなさい、
他のドメイン関連の質問もありますが、正規表現が適切に機能していないか、複雑すぎるか、サブドメイン、プロトコル、およびファイルパスを持つURLのいずれかです。
私はもっと簡単です。ドメイン名を検証する必要があります。
google.com
stackoverflow.com
したがって、最も生の形式のドメイン-wwwのようなサブドメインでさえありません。
- 文字はa-z |のみにしてくださいA-Z | -9およびピリオド(。)およびダッシュ(-)
- ドメイン名の部分は、ダッシュ(-)(e.g。-google-.com)で開始または終了しないでください
- ドメイン名の部分は1〜63文字である必要があります
拡張子(TLD)は、今のところ#1ルールの下にあるものであれば何でもかまいません。後でリストに対して検証するかもしれませんが、1文字以上でなければなりません。
編集:TLDは明らかに2〜6文字です
no。4改訂: TLDは.co.ukのようなものを含む必要があるため、実際には「サブドメイン」とラベル付けする必要があります。最初のドットの後に、ルール#1の下に1つ以上の文字があるはずです
どうもありがとう、私がやってみたことを信じて!
まあ、それは とても簡単です あなたの特定の要件を考えると、見た目より少しひそかな(コメントを参照):
/^[a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]\.[a-zA-Z]{2,}$/
ただし、これにより多くの有効なドメインが拒否されることに注意してください。
これは少し古い記事であることは知っていますが、ここのすべての正規表現には、IDNドメイン名のサポートという非常に重要なコンポーネントが1つ欠けています。
IDNドメイン名 xn--で始まります。ドメイン名で拡張UTF-8文字を有効にします。たとえば、「♡.com」が有効なドメイン名であることをご存知ですか?ええ、「ラブハートドットコム」!ドメイン名を検証するには、 http://xn--c6h.com/ 検証に合格する必要があります。
この正規表現を使用するには、ドメインを小文字に変換し、IDNライブラリを使用してドメイン名をACEにエンコードする必要があります(「ASCII互換エンコーディング」とも呼ばれます)。良いライブラリの1つはGNU-Libidnです。
idn(1)は、国際化ドメイン名ライブラリへのコマンドラインインターフェイスです。次の例では、UTF-8のホスト名をACEエンコーディングに変換します。結果として生成されるURL https://nic.xn--flw351e/ は、ACEエンコードの https:// nic。谷歌/ と同等のものとして使用できます。
$ idn --quiet -a nic.谷歌
nic.xn--flw351e
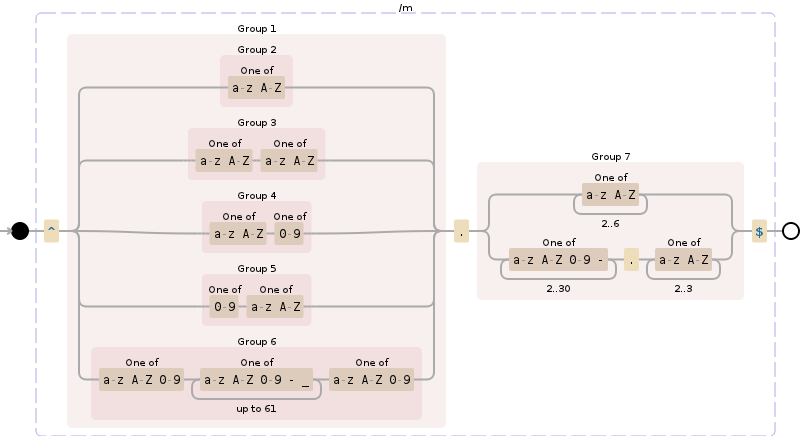
この魔法の正規表現は、mostドメインをカバーする必要があります(ただし、見逃した有効なEdgeケースが多数あると確信しています)。
^((?!-))(xn--)?[a-z0-9][a-z0-9-_]{0,61}[a-z0-9]{0,1}\.(xn--)?([a-z0-9\-]{1,61}|[a-z0-9-]{1,30}\.[a-z]{2,})$
ドメイン検証正規表現を選択するとき、ドメインが次と一致するかどうかを確認する必要があります。
- xn--stackoverflow.com
- stackoverflow.xn--com
- stackoverflow.co.uk
これらの3つのドメインがパスしない場合、正規表現が正当なドメインを許可していない可能性があります!
詳細については、 オラクルの国際言語環境ガイドの国際化ドメイン名のサポートページ をご覧ください。
ここで正規表現を試してみてください: http://www.regexr.com/3abjr
ICANNは 委任されたtldのリスト を保持します。これはIDNドメインの例を見るために使用できます。
編集:
^(((?!-))(xn--|_{1,1})?[a-z0-9-]{0,61}[a-z0-9]{1,1}\.)*(xn--)?([a-z0-9][a-z0-9\-]{0,60}|[a-z0-9-]{1,30}\.[a-z]{2,})$
この正規表現は、ホスト名の末尾に「-」が有効であるとマークされているドメインを停止します。さらに、無制限のサブドメインを許可します。
私の正規表現は次です:
^[a-zA-Z0-9][a-zA-Z0-9-_]{0,61}[a-zA-Z0-9]{0,1}\.([a-zA-Z]{1,6}|[a-zA-Z0-9-]{1,30}\.[a-zA-Z]{2,3})$
i.oh1.meおよびwow.british-library.uk
UPD
更新されたルールはこちら
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][a-zA-Z0-9-_]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,6}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
https://www.debuggex.com/r/y4Xe_hDVO11bv1DV
ドメインラベルの開始または終了で-または_をチェックするようになりました。
私の賭け:
^(?:[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?\.)+[a-z0-9][a-z0-9-]{0,61}[a-z0-9]$
説明:
ドメイン名はセグメントから構築されます。これが1つのセグメントです(最終を除く):
[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?
1〜63文字を使用でき、「-」で開始または終了することはできません。
「。」を追加しますそれに、少なくとも1回繰り返します:
(?:[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?\.)+
次に、2〜63文字の最終セグメントを添付します。
[a-z0-9][a-z0-9-]{0,61}[a-z0-9]
ここでテスト:http://regexr.com/3au3g
ほんのわずかな修正-最後の部分は6までです。したがって、
^[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,6}$
最長のTLDはmuseum(6文字)- http://en.wikipedia.org/wiki/List_of_Internet_top-level_domains
この回答は、ホスト名(電子メールホスト名など)ではなく、ドメイン名(サービスRRを含む)に対するものです。
^(?=.{1,253}\.?$)(?:(?!-|[^.]+_)[A-Za-z0-9-_]{1,63}(?<!-)(?:\.|$)){2,}$
基本的には mkyongの答え であり、さらに:
- 長さプレフィックスとヌルルートを含む255オクテットの最大長。
- 末尾の「。」を許可明示的なDNSルートの場合。
- サービスドメインRRの先頭の「_」を許可します(バグ:_ラベルに最大15文字を強制しません。また、サービスRRよりも少なくとも1つのドメインを必要としません)
- すべての可能なTLDに一致します。
- サブドメインラベルをキャプチャしません。
部品別
先読み、オプションの末尾リテラル '。'で^ $の最大長を253文字に制限してください
(?=.{1,253}\.?$)
先読み、次の文字は「-」ではなく、「_」は次の「。」の前の文字に続きません。つまり、ラベルの最初の文字が「-」ではなく、最初の文字のみが「_」であることを強制します。
(?!-|[^.]+_)
ラベルごとに1〜63文字の許可された文字。
[A-Za-z0-9-_]{1,63}
後ろ、前の文字は「-」ではありません。つまり、ラベルの最後の文字が「-」ではないことを強制します。
(?<!-)
「。」を強制するオプションを除く最後を除くすべてのラベルの最後。
(?:\.|$)
ほとんどが上から組み合わされて、これには少なくとも2つのドメインレベルが必要です。 TLDまたは非修飾の相対サブドメインを許可する場合は、{2、}から+に変更します(localhost、myrouter、toなど)。
(?:(?!-|[^.]+_)[A-Za-z0-9-_]{1,63}(?<!-)(?:\.|$)){2,}
ユニットテスト この式の場合。
受け入れられた答えが私のために機能しない、これを試してください:
^((?!-)[A-Za-z0-9-] {1,63}(?<!-)\。)+ [A-Za-z] {2,6} $
検証のためにこれをご覧ください nit Test Cases .
他の回答でドメイン名検証ソリューションの正しい方向を示していただきありがとうございます。ドメイン名はさまざまな方法で検証できます。
検証する必要がある場合IDNドメインの人間が読めるフォーム、正規表現\p{L}が役立ちます。これにより、任意の言語の任意の文字に一致させることができます。
最後の部分にもハイフンが含まれている可能性があることに注意してください! punycodeでエンコードされているため、中国語名はtldにUnicode文字を含む場合があります。
たとえば次のようなソリューションになりました。
- google COM
- masełkowski.pl
- maselkowski.pl
- m.maselkowski.pl
- www.masełkowski.pl.com
- xn--masekowski-d0b.pl
- 中国互联网络信息中心。中国
- xn--fiqa61au8b7zsevnm8ak20mc4a87e.xn--fiqs8s
正規表現:
^[0-9\p{L}][0-9\p{L}-\.]{1,61}[0-9\p{L}]\.[0-9\p{L}][\p{L}-]*[0-9\p{L}]+$
注:この正規表現は非常に寛容です。現在のドメイン名では文字セットが許可されています。
UPDATE:a-aA-Z\p{L}は\p{L}と同じであるため、さらに簡素化されます
注2:唯一の問題は、masełk..owski.plのように、二重ドットを含むドメインと一致することです。誰かがこれを修正する方法を知っている場合は改善してください。
コメントするにはまだ十分な担当者がいません。 pakaの解決策に応えて、3つの項目を調整する必要があることがわかりました。
- ダッシュとアンダースコアは、ダッシュが範囲として解釈されるために移動されました(「0-9」のように)
- 多くのサブドメインを持つドメイン名の完全な停止を追加しました
- TLDの潜在的な長さを13に拡張しました
前:
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][a-zA-Z0-9-_]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,6}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
後:
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][-_\.a-zA-Z0-9]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,13}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
^[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,7}$
[ドメイン-小文字と0〜9のみ] [ハイフンを使用できます] + [TLD-小文字のみ、2〜7文字の長さでなければなりません]
http://rubular.com/ は正規表現のテストに最適です!
編集:Dan Caddiganが指摘したように、「。rentals」のTLDを最大7文字に更新しました。
^((localhost)|((?!-)[A-Za-z0-9-]{1,63}(?<!-)\.)+[A-Za-z]{2,253})$
@mkyong、私の答えの根拠に感謝します。より長い許容ラベルをサポートするように変更しました。
また、「localhost」は技術的には有効なドメイン名です。国際化ドメイン名に対応するために、この回答を修正します。
新しいgTLDの場合
/^((?!-)[\p{L}\p{N}-]+(?<!-)\.)+[\p{L}\p{N}]{2,}$/iu
^[a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]\.[a-zA-Z]+(\.[a-zA-Z]+)$
以下に例を含む完全なコードを示します。
<?php
function is_domain($url)
{
$parse = parse_url($url);
if (isset($parse['Host'])) {
$domain = $parse['Host'];
} else {
$domain = $url;
}
return preg_match('/^(?!\-)(?:[a-zA-Z\d\-]{0,62}[a-zA-Z\d]\.){1,126}(?!\d+)[a-zA-Z\d]{1,63}$/', $domain);
}
echo is_domain('example.com'); //true
echo is_domain('https://example.com'); //true
echo is_domain('https://.example.com'); //false
echo is_domain('https://localhost'); //false
すでに指摘したように、サブドメインを実際的な意味で伝えることは明らかではありません。 使用する この正規表現は、野生で発生するドメインを検証します。それは私が知っているすべての実用的なユースケースをカバーしています。新しいものは大歓迎です。 当社のガイドライン によれば、非キャプチャグループと貪欲なマッチングを回避します。
^(?!.*?_.*?)(?!(?:[\d\w]+?\.)?\-[\w\d\.\-]*?)(?![\w\d]+?\-\.(?:[\d\w\.\-]+?))(?=[\w\d])(?=[\w\d\.\-]*?\.+[\w\d\.\-]*?)(?![\w\d\.\-]{254})(?!(?:\.?[\w\d\-\.]*?[\w\d\-]{64,}\.)+?)[\w\d\.\-]+?(?<![\w\d\-\.]*?\.[\d]+?)(?<=[\w\d\-]{2,})(?<![\w\d\-]{25})$
証明と説明: https://regex101.com/r/FLA9Bv/9
ドメインを検証するときに選択する2つのアプローチがあります。
書籍によるFQDNマッチング(理論上の定義、実際にはめったに見られない):
- 最大253文字( RFC-1035/3.1 、 RFC-2181/11 による)
- ラベルあたり最大63文字( RFC-1035/3.1 、 RFC-2181/11 )
- 任意の文字が許可されます( RFC-2181/11 に従って)
- TLDをすべて数字にすることはできません( RFC-3696/2 による)
- FQDNは、ルートゾーン(末尾のドット)を含む完全な形式で記述できます
実用的/保守的なFQDNマッチング(実際の定義、実際に期待され、サポートされている):
- 次の例外/追加と一致する書籍別
- 有効な文字:
[a-zA-Z0-9.-] - ラベルはハイフンで開始または終了できません( RFC-952 および RFC-1123/2.1 による)
- TLDの最小長は2文字、最大長は現在の既存レコードごとに24文字
- 末尾のドットと一致しない
^ [a-zA-Z0-9] [-a-zA-Z0-9] + [a-zA-Z0-9]。[az] {2,3}(。[az] {2,3}) ?(。[az] {2,3})?$
動作する例:
stack.com
sta-ck.com
sta---ck.com
9sta--ck.com
sta--ck9.com
stack99.com
99stack.com
sta99ck.com
拡張機能でも動作します
.com.uk
.co.in
.uk.edu.in
動作しない例:
-stack.com
最長のドメイン拡張子".versicherung"でも機能します
/^((([a-zA-Z]{1,2})|([0-9]{1,2})|([a-zA-Z0-9]{1,2})|([a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]))\.)+[a-zA-Z]{2,6}$/
([a-zA-Z]{1,2})-> 2文字のみを受け入れます。([0-9]{1,2})-> 2つの数字のみを受け入れる場合
何かが2つの([a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9])を超える場合、この正規表現がそれを処理します。
少なくとも1回マッチングを行いたい場合は、+が使用されます。