ネガティブな先読みを理解する
簡単な例でネガティブな先読みがどのように機能するかを理解しようとしています。たとえば、次の正規表現について考えてみます。
a(?!b)c
ネガティブな先読みはポジションと一致すると思いました。したがって、その場合、正規表現は、厳密に3文字を含み、abcではない任意の文字列に一致します。
しかし、このデモに見られるように、それは真実ではありません。どうして?
先読みは文字を消費しません。先読みが一致するかどうかをチェックするだけです。
_a(?!b)c
_したがって、ここではaを照合した後、bが続かないかどうかをチェックしますが、そのnot文字(c)を消費せず、その後にcが続きます。
a(?!b)cがacとどのように一致するか
_ac
|
a
ac
|
(?!b) #checks but does not consume. Pointer remains at c
ac
|
c
_ポジティブな先読み
ポジティブルックアヘッドは、ルックアヘッドのパターンと一致しようとするという点で似ています。一致する可能性がある場合、正規表現エンジンは残りのパターンの一致を続行します。できない場合、一致は破棄されます。
例えば。
abc(?=123)\d+マッチング_abc123_
_abc123
|
a
abc123
|
b
abc123
c
abc123 #Tries to match 123; since is successful, the pointer remains at c
|
(?=123)
abc123 # Match is success. Further matching of patterns (if any) would proceed from this position
|
abc123
|
\d
abc123
|
\d
abc123 #Reaches the end of input. The pattern is matched completely. Returns a successfull match by the regex engine
|
\d
_@Antario、私はしばらくの間正規表現のネガティブな先読み/後ろ向きのケースについて混乱しました、そして this サイトは素晴らしい説明をしています。
したがって、あなたの例では、リテラル「a」があり、その後にリテラル「b」がなく、ISの後にリテラル「c」が続くということです。
これはあなたが使用したものとは異なる正規表現デバッガーであり、個人的に役立つと思うより視覚的な答えを提供します:)
a(?!b)c
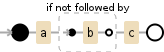
a(?!b)cはacにのみ一致します。これは、aの後に「notb」(消費されない)が続く唯一の方法であり、その場合、cはacです。
したがって、その場合、正規表現は、厳密に3文字を含み、abcではない任意の文字列に一致します。
これは完全に正しくありません。この正規表現は、最初の記号がaで、その後がcであり、内部にbがないシーケンスを検索していることを示しています。
たとえば、a(?!b).はacまたはafのいずれかに一致します。これは、.を介した最後のシンボルに制限がないためです。